I encountered a few issues when trying to parallelize the execution of GAMSPy models which I wanted to share. Maybe someone knows a sensible workaround.
What I want to do: I have a large model containing a set representing hourly time steps, e.g. for the duration of a year. I have decomposed this model into 8760 smaller ones representing the sub-problems created by removing all time dependencies. Now I want to solve these models in parallel, ideally by using the standard libraries given in Python (concurrent.futures in my case). I cannot share my whole code, but a sketch of the parallelization part looks like this:
mi = ip.ModelInput(source_file) # object containing all necessary data for the model
def f(t):
mi_t = mi.view(t) # function creating view of mi, essentially sampling the time-dependent data
ct, m = build.build(mi_t) # function which builds the GAMSPy model
m.solve()
return ct
def main():
ts = list(range(8760))
executor = concurrent.futures.ProcessPoolExecutor()
results = list(
executor.map(
f,
ts,
chunksize=len(ts) // multiprocessing.cpu_count()
)
)
The problems I encountered:
gamspy.Container is not picklable: This is apparently necessary to gather the results after execution. This was easily fixed by letting f() return the individual records DataFrames that are of interest.
The writing of temporary files by GAMSPy alerts the Windows “Antimalware Service Executable”, which dramatically slows down the execution: At least that’s my assumption, and it’s very likely to be true (30-50% CPU usage by this service when executing, while the processes are at ~0.1%). This may also be due to my organization’s restrictive security policy, but nonetheless is a problem. I have tried creating a local working_directory for each process, but the rules apparently also apply there.
I have the option to parallelize this differently on a server, but would prefer to do it locally. Is there maybe another option to do so?
Container is not pickable because it maintains a socket connection between GAMS and GAMSPy. It is better either to return the DataFrames as you said or write the Container to the disk by using Container.write and load it afterwards to another Container.
I will investigate this. Do you know your license type (local license or network license)? I will try to reproduce this problem but it would be really nice if you can provide a script with a minimal example (you can just use dummy data).
Ah, that makes sense. I wanted to avoid I/O, but this would be fine if I really want to keep the whole container.
This was with a local license. I created a minimal example for you. Note that I had to rename it to “.txt” because this forum does not accept “.py” files. About the example: When playing around with the size of the individual problems via the “size” parameter in main(), I found that the CPU usage of the “Antimalware Service Executable” is higher with a smaller problem size. I guess this supports the assumption, since this leads to faster creation of temporary files. parallelization_minimal_example.txt (1.08 KB)
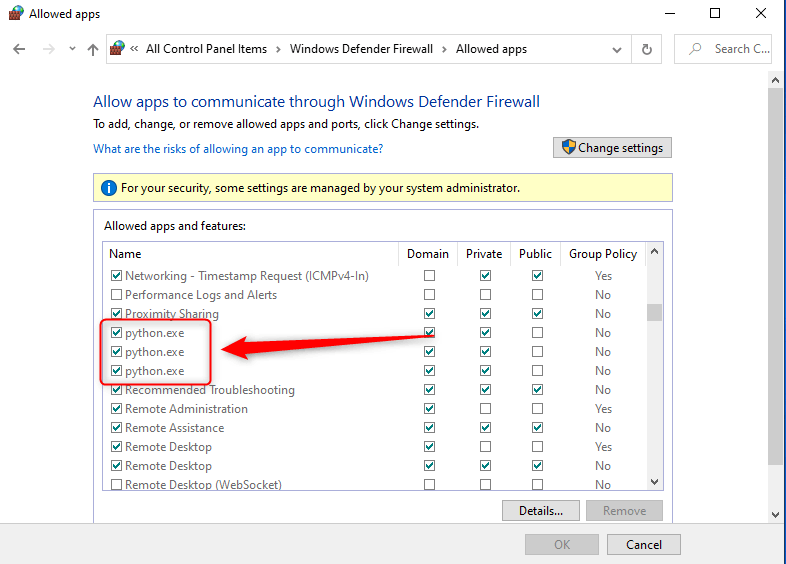
After I added python.exe to the allowed apps on Windows Defender settings and set the working directory as “.”, cpu usage of Windows Defender dropped around 8-10% after it stabilized (at the beginning it shoots up to 30-40%) while the actual jobs are around 1%. Here is how you can do it:
Go to Windows Defender and add the Python executable that you are using to the list of allowed apps.
Still, 8-10% for Windows Defender is quite high. I will continue to investigate it.
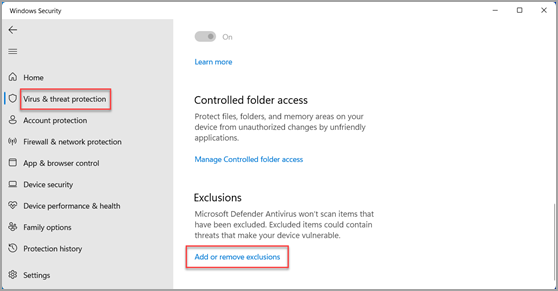
After excluding the working directory of GAMSPy from Windows Defender settings, the resource usage of Windows Defender dropped quite a bit but still it consumes more resources than the actual program. You can do the exclusion as follows:
I don’t think there is much we can do after this point. If you have a performance critical experiment, it’s probably better to use a Unix-based operating system.
For the sake of completeness: On UNIX systems, other problems occur with the parallelization of GAMSPy. I found that you should not set the solver_link_type="memory" but rather keep the default, which is reading from disk. Otherwise, the execution either freezes at some point or does not finish properly for some reason. See Github issue: Error with multiple runs in parallel and `solver_link_type="memory"` · Issue #14 · GAMS-dev/gamspy · GitHub
However, I have not investigated further than the toy example shown there.
I followed your advice of writing the Container to disk using Container.write and loading it onto another container. It works well however, I realised that the written container does not contain information on the initialised equations. I.e. In my model, I introduce sets, variables, parameters and equations. Then, I load the data and initialise the equations. When I write it to the “.gdx” file, and then load it, I get an error that equations were not initialised. So in order to parallelise the work I need to reinitialise equations in every iteration. Is there any way around it?